精细性能指标
目录
精细性能指标¶
注意
这是一个实验性功能,可能会在没有弃用周期的情况下快速变化。
您可能想探究 Dask 工作负载主要花费时间的地方;不仅是在哪些任务上,还在运行这些任务时正在做什么。Dask 会自动收集精细性能指标,通过按任务分解计算的端到端运行时,并在每个任务中按完成它所采取的一系列活动来回答这个问题。
为了查看这些指标,您可以简单地:
端到端运行您的工作负载
打开 Dask 控制面板(LocalCluster 默认地址:https://:8787)
选择
More...->Fine Performance Metrics
或者,如果您使用 Jupyter Lab 和 dask-labextension,您可以直接将 Fine Performance Metrics 小部件拖放到您的 Jupyter 控制面板上。
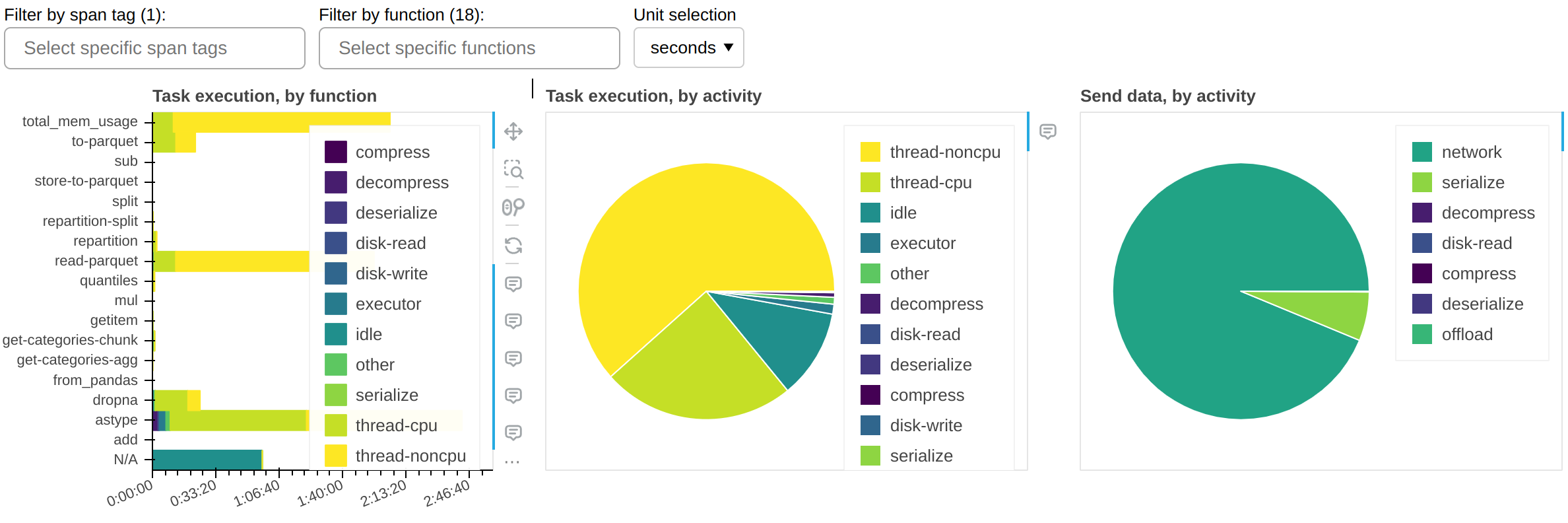
中心面板(按活动划分的任务执行)显示集群 cumulatively(累积地)花费在哪些活动上,针对所有当前可见的函数。最重要的活动是:
thread-cpu任务在工作节点上运行时花费的 CPU 时间。这通常是“好的”时间;换句话说,这与您在单个 CPU 上串行运行工作负载所花费的时间相同 - 但已在集群上的可用 CPU 数量上实现了并行化。
thread-noncpu任务在工作节点上运行时花费的墙钟时间与 CPU 时间之间的差异。这通常是 I/O 时间、GPU 时间、CPU 竞争或 GIL 竞争。如果您在整个工作负载中观察到大量的此类时间,您可能需要按函数进行分解,并隔离那些已知执行 I/O 或 GPU 活动的函数。
idle工作节点拥有空闲线程,但没有东西可运行的时间。这通常是由于工作负载无法充分利用集群上的所有线程、调度器和工作节点之间的网络延迟或调度器上 CPU 负载过高造成的。此衡量不包括整个集群完全空闲时花费的时间。
disk-read,disk-write,compress,decompress由于可用内存不足而将数据溢出/解除溢出到磁盘所花费的时间。请参阅 工作节点内存管理。
executor,offload,other这是 Dask 代码的开销,通常可以忽略不计。但是,它可能因 GIL 竞争和溢出/解除溢出活动而增加。
所示时间的总和应该大致等于工作负载的端到端运行时乘以集群上的线程数。
左侧面板(按函数划分的任务执行)显示与中心面板相同的信息,但按函数进行了分解。
右侧面板(按活动划分的数据发送)显示网络传输时间。请注意,其中大部分应该与任务执行并行进行,因此可能不会产生影响。只有当您有非常大的 idle 时间时,才需要关注此项。
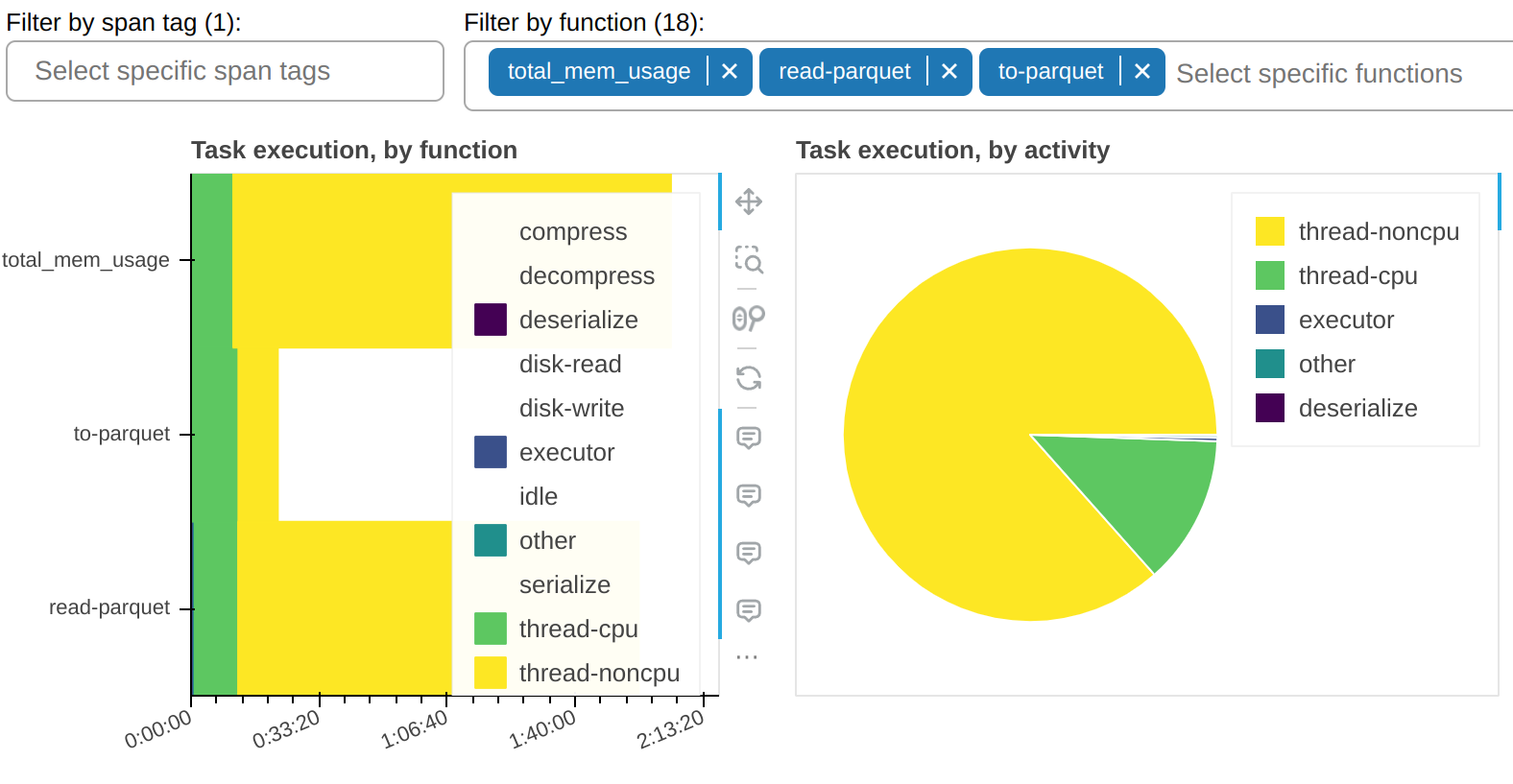
有一个过滤器允许您仅显示选定的函数。在样本截图中,您可以看到大部分 thread-noncpu 时间集中在(正如预期)那些已知是 I/O 密集型的函数中。这里它们被单独挑出:
这里是所有其他花费非琐碎时间量的函数:
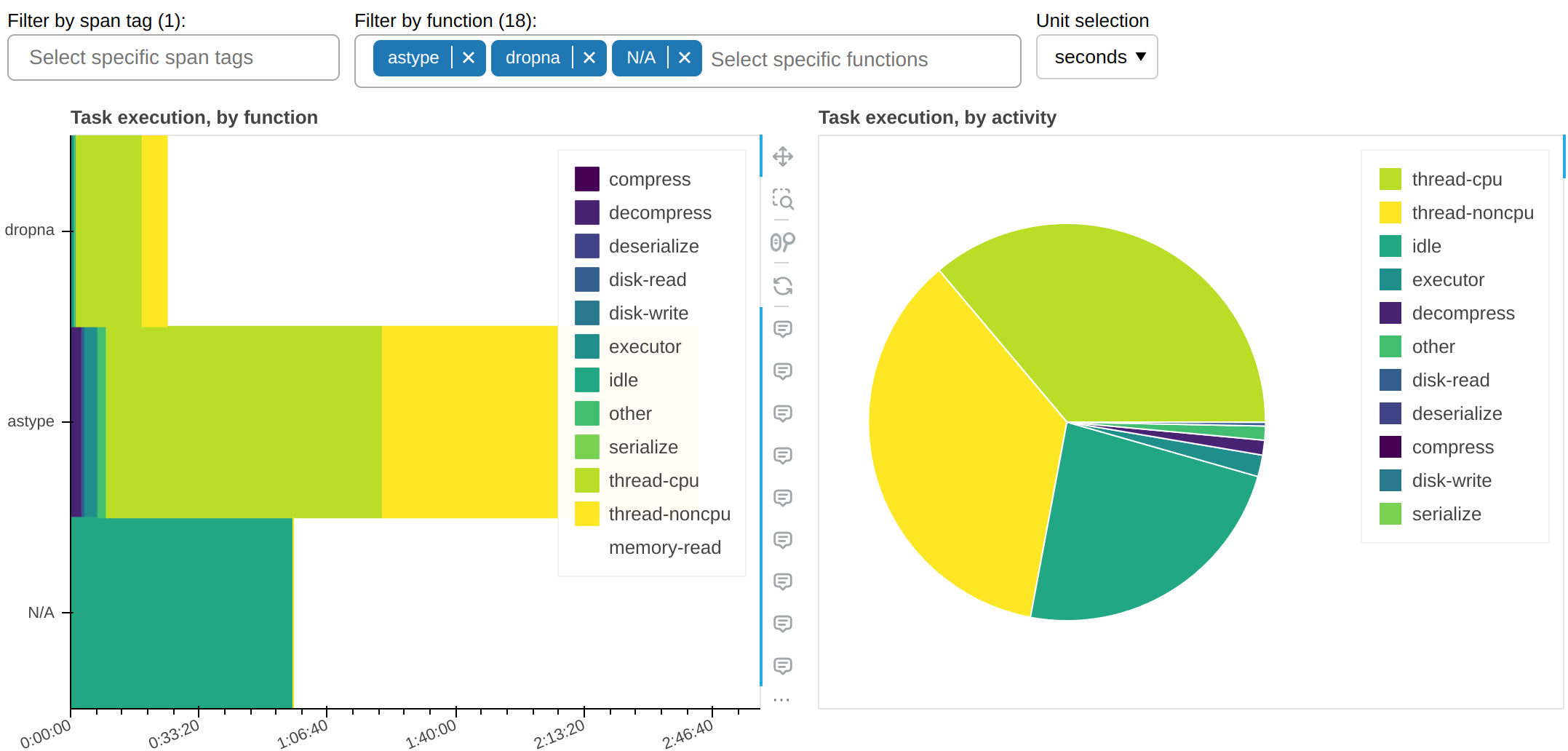
这告诉我们一个重要的信息:为什么 astype,一个纯 CPU 函数,花费如此多的时间占用工作节点的线程却没有累积任何 CPU 时间?答案几乎肯定是它没有正确释放 GIL。
精细性能指标收集的不仅仅是墙钟时间。我们可以将单位更改为字节:
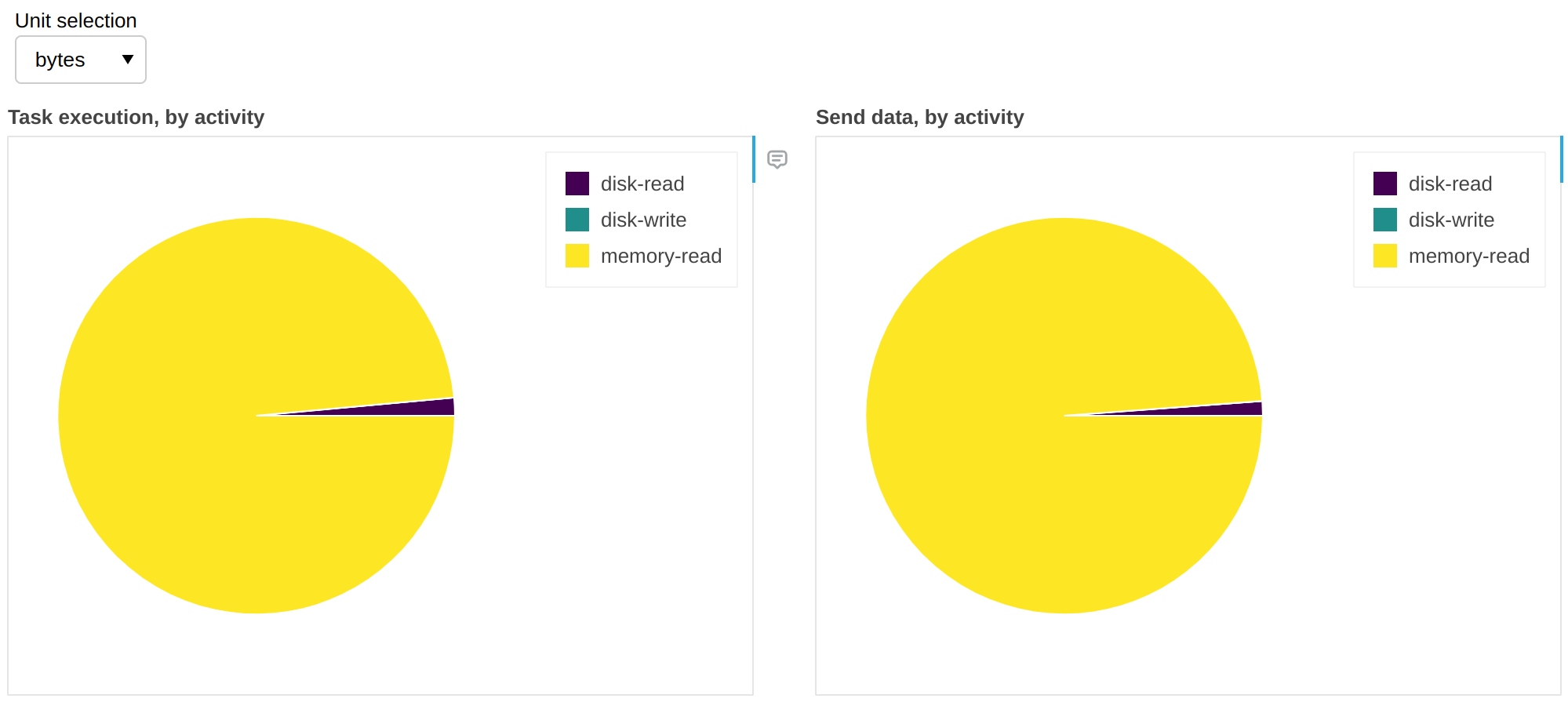
上述信息使我们能够深入了解溢出/解除溢出活动(请参阅 工作节点内存管理)。在此工作流中,99% 的情况下有足够的 RAM 来容纳所有数据,并且不需要从磁盘检索;换句话说,我们对 99% 的数据有缓存命中,这意味着如果我们增加 RAM 不会获得任何好处,但如果我们减少 RAM 则可能会开始出现速度下降。
任务前缀足够吗?¶
单个任务前缀可能粒度太细;反之,同一个任务前缀可能出现在工作流中非常不同的部分。您的代码库可能足够复杂,以至于无法直接 pinpoint 负责特定任务前缀的客户端代码。
Span 允许您将这些指标分解为宏观块(例如,数据加载、预处理等)。
高级用户 API¶
在大多数情况下,精细性能指标只是“工作正常”;作为用户,您无需更改客户端代码。
如果您在集群上运行自定义任务(例如,通过 submit()、map_blocks() 或 map_partitions()),您可能希望自定义它们产生的指标。例如,您可能希望将 I/O 时间与 thread-noncpu 分开:
from distributed.metrics import context_meter
@context_meter.meter("I/O")
def read_some_files():
...
future = client.submit(read_some_files)
在上面的示例中,自定义函数 read_some_files 花费的墙钟时间将被记录为“I/O”,这是一个完全任意的活动标签。
或者,您可能只想以这种方式标记部分时间:
def read_some_files():
with context_meter.meter("I/O"):
data = read_from_network(...)
return preprocess(data)
在上面的示例中,函数被分为一个 I/O 密集型阶段 read_from_network 和一个 CPU 密集型阶段 preprocess。distributed.metrics.context_meter.meter() 上下文管理器将 read_from_network 花费的时间记录为 I/O,而 preprocess 花费的时间仍将记录为 thread-cpu 和 thread-noncpu 的混合(后者可能例如突出 GIL 竞争)。
注意
distributed.metrics.context_meter.meter() 上下文管理器包装了在工作节点上运行的代码,位于单个任务中。如果用于修饰定义 Dask 图的客户端代码,它将不起作用。请参阅 Span 获取相关信息。
最后,您可能想报告一个不仅仅是墙钟时间的指标。例如,如果您从 S3 Infrequent Access 存储读取数据,您可能希望跟踪它以了解您的花费:
def read_some_files():
data = read_from_network(...)
context_meter.digest_metric("S3 Infrequent Access", sizeof(data), "bytes")
return data
同样,“S3 Infrequent Access”是一个完全任意的活动标签,“bytes”是一个完全任意的度量单位。
- distributed.metrics.context_meter.digest_metric(label: collections.abc.Hashable, value: float, unit: str) None¶
为任意定量指标调用当前设置的上下文回调。
- distributed.metrics.context_meter.meter(label: collections.abc.Hashable, unit: str = 'seconds', func: collections.abc.Callable[[], float] = <built-in function perf_counter>, floor: typing.Union[float, typing.Literal[False]] = 0.0) collections.abc.Iterator[distributed.metrics.MeterOutput]¶
便利的上下文管理器或装饰器,在包装代码之前和之后调用 func(),计算差值,最后调用
digest_metric()。如果 unit==’seconds’,它还会减去在上下文中执行的具有相同单位的任何其他对
meter()或digest_metric()的调用,以便总和严格可加。
开发者规范¶
目标受众
本节仅对维护 Dask 或编写调度器扩展(例如,创建替代控制面板或长期存储指标)的开发者感兴趣。
精细性能指标收集于:
每个工作节点上
全局调度器上
Span 上
在工作节点上,它们通过 distributed.core.Server.digest_metric() 收集并存储在 Worker.digests_total 映射中。
它们以以下格式存储:
("execute", span_id, task_prefix, activity, unit): value("gather-dep", activity, unit): value("get-data", activity, unit): value("memory-monitor", activity, unit): value
在每次心跳时,它们会同步到调度器,填充 Scheduler.cumulative_worker_metrics 映射,格式如下:
("execute", task_prefix, activity, unit): value("gather-dep", activity, unit): value("get-data", activity, unit): value("memory-monitor", activity, unit): value
由于这里的 execute 指标没有 span_id,因此来自工作节点的多个记录可能已经在调度器上的单个记录中累加。
execute 指标也可以在 Span 上找到,位于 Scheduler.extensions["spans"].spans[span_id].cumulative_worker_metrics,以以下格式表示:
("execute", task_prefix, activity, unit): value
注意事项¶
在
Worker.digests_total和Scheduler.cumulative_worker_metrics中,您还会找到与精细性能指标无关的键,它们不一定是元组。由于自定义指标(请参阅上一节),
activity大多数时候是字符串,但并非总是。即使没有自定义指标,未来也可能会添加更细粒度的活动,因此硬编码测试它们绝不是一个好主意。